Online games and trivia apps have grown tremendously in the last 10 years and specifically in 2020, Mobile gaming has become a $77.2 billion global business. At the same time, the mobile gaming industry recorded 12% more players in 2020 than in 2019, with over 2.5 billion players. Even though the raging pandemic destroyed many businesses across several industries, the case was reversed for the gaming industry.
Trivia, quizzes, etc are now not only limited to games but, the other online environments are also adopting game-based features to improve users’ experiences. A clear example of that is the use of game elements within non-game contexts, for example:- Gaming-based learning, Gamification in Content personalization, Game-based marketing, etc.
The one most important element of game-based environments at which user will always look is Leaderboard which sort players against a particular criterion, usually the underlying score, and are thus indicators of progress that relate to the player’s performance to the performance of others looking for intrinsic motivation.
Implementing a leaderboard could be easy but, when the number of users raised to several dozens of thousands, a lot of response time problems start to appear. And, in our case, we had to show the player’s current ranking along with the leaderboard in real-time after each round and the delay between the 2 rounds was of 20 seconds. So, we really wanted it to be too fast say in a couple of seconds and it should work for at least 1 million active users.
We could use any of the below-mentioned approaches to implement the Leaderboard, but even with the lower input size, there is a considerable difference between “in-memory” approaches and the HDD-based, that is,between the data structures running in the RAM and the database solution.
##Classic Database Approach Saving all the information in the Database and using DB’s internal functions to calculate the rank(ORDER_BY and RANK()). It is very Inefficient, probably works faster for users under 50000 with time complexity of O(N2), falls down easily when N is high ex:- above 1 lakh.
##Bucket Approach (In-memory + Database) One approach was to divide the scores into buckets say for example in our case we have points of 10 for each correct answer and the maximum a player can score is 400(40 rounds) for a complete contest. So, we can have a Bucket with attributes (range and counter) stored in Redis. Now, we can divide the scores into buckets (Bucket 1 = 0-100), (Bucket 2 = 100-200), (Bucket 3 = 200-300), (Bucket 4 = 300-400) and each time we add the score for a player we will find out the bucket based on the score, we will increment the bucket’s counter and will save the reference of the selected Bucket in the player’s record. And when we need to calculate the player’s rank we’ll fetch the bucket referenced in a player record we’ll find out the number of players who have more scores than the current player in the current Bucket along with the value of counters of the buckets that precedes current bucket. For example(for playerId: 9 the bucket stored in it is 2 and its current score is 130. Now, in order to calculate its rank we need to calculate the number of users who have scores >= 130 + the value of the counter of bucket 3 + the value of the counter of bucket 4 ). Again in this approach, we need to pre-create the buckets and decide their range. Also, the last query to calculate the number of players who have more scores than the current player in a bucket can be slow if our buckets are so big and we have a lot of users in each bucket.

##Self Balanced Binary Search Tree (SBBST) An SBBST is a particular kind of binary search tree, it means each node is linked at most to two subtrees, commonly denoted left and right. A node with no subtrees is called a leaf, and the unique top of the whole tree is called a root. Now, besides these features, a binary search tree must fulfill a condition: each node must be greater than all nodes in its left subtree, and not greater than any in the right subtree. It is called balanced because the height of the left and right subtree of any node differs by not more than 1.
In our case, each of the nodes would store 6 attributes, playerId, score, a pointer to the left subtree, a pointer to the right subtree, a pointer to the parent, and size. The size of the current node refers to the number of nodes below and including it.
node.size = (node.left).size + (node.right).size + 1.
Also, note that we will create a node on the left subtree for the duplicate keys i.e for the same score of 2 different players.
###Ranking Before running the algorithm, we need to build and balance the binary tree with the players’ scores. The time complexity of building the tree would be in O(NlogN). Once we have SBBST ready, we can compute the ranking operation using an algorithm as presented below.
getRank(score, playerId) {
const { root } = this._tree;
if (!root) {
logger.info("tree doesn't have any root");
return -1;
}
const node = this._tree.search(score, playerId);
if (!node) {
logger.info("Node doesn't found for this Score", score);
return -1;
}
let rank = node.right.size + 1;
let anotherNode = node;
while (anotherNode != node) {
if (anotherNode == anotherNode.parent.left) {
rank = rank + anotherNode.parent.right.size + 1;
}
anotherNode = anotherNode.parent;
}
return rank;
}So, It starts with finding the node based on the given score and playerId, if the node is found it sets the rank as the size of its right child + 1 (including itself) and then it goes up to the root one level at the time and adds the size(no of nodes preceding) to the rank accordingly.
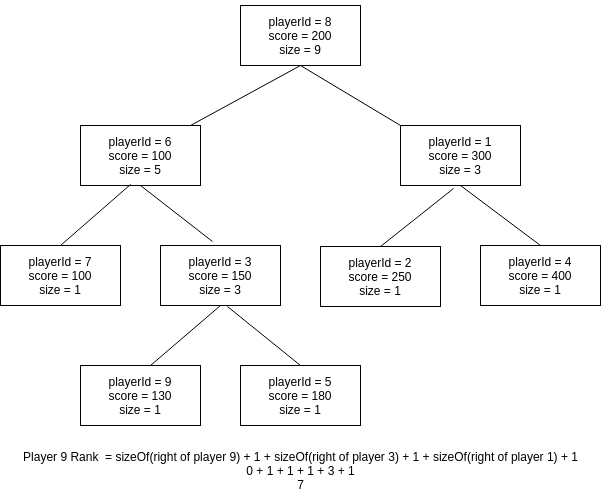
Basically, this algorithm calculates the number of nodes preceding the current node (with given score and playerId) in a reverse in-order walk of the tree.
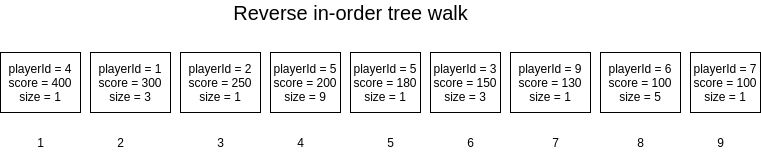
Now, notice that, in the previous algorithm, once the node x is found it goes up to the root one level at a time, which means that the running time is proportional to the tree height. Therefore, that is why the ranking operation also runs in O(logN).
The total time complexity of the entire ranking algorithm for N players is NlogN(building the tree) + NlogN = 2NlogN
###Leaderboard And, if we just need to show the Leaderboard, we can take the advantage of the binary search structure of the tree, and traverse the tree in a backward “in-order” direction which will give the sorted list of players in O(N).
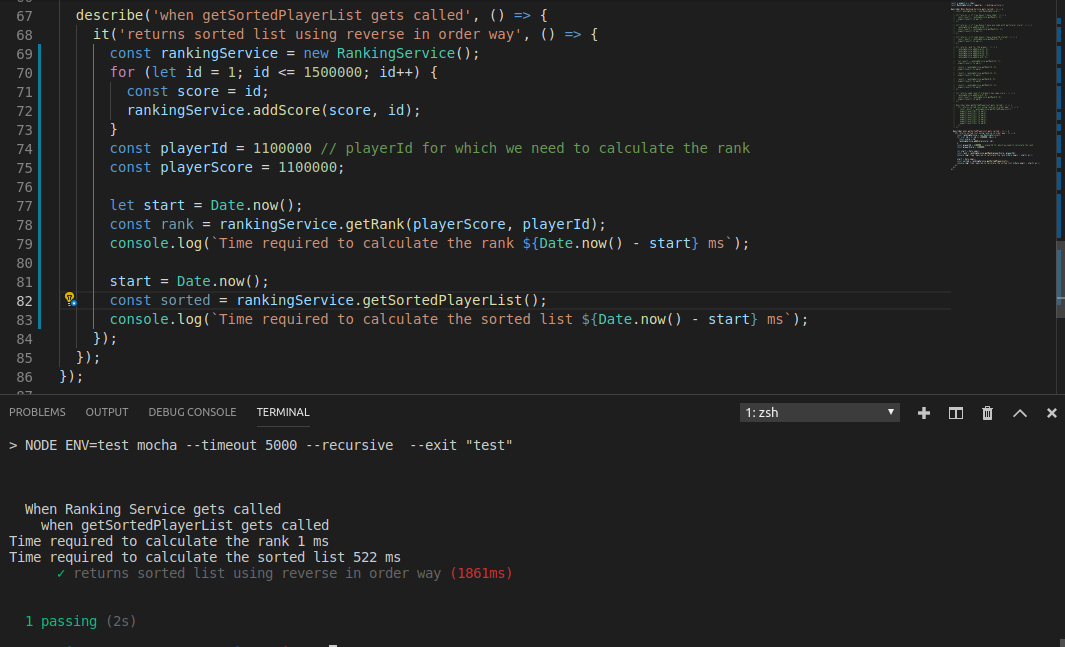
###Results From the algorithmic point of view, this solution surpasses typical solutions as the ones based on databases, as well as other “in-memory,” bucket approach mentioned above and It achieves speedups when the N(number of players) is too high. So, we tried running some test cases for the above algorithm and the responses were amazingly fast, for example:- We ran this algorithm for 1.5 million users and as it can be seen below, it took just 1 ms to calculate the rank and 522 ms to calculate the Leaderboard.
##References:- https://techcrunch.com/2019/08/22/mobile-gaming-mints-money/ https://www.businessofapps.com/insights/mobile-gaming-industry-statistics-and-trends-for-2021/ https://www.hindawi.com/journals/ijcgt/2018/3234873/