I still remember those days when Mobile Devs used to argue with the Backend teams regarding the unnecessary data coming in the APIs, and the reason is we used to create the General-Purpose API Backend which could be consumed by any of the clients(Web/Mobile) untill BFF (Backend for Frontend) pattern was introduced by SoundCloud in 2015. But having BFF has its own caveats like, there is a high probability that each BFF may implement similar capabilities with different teams, easily doubling (or more) the cost of development and as we segment backends for each constituent frontend, the number of deployable units increases.
Does that mean GraphQL is going to replace BFF ?. Well, some GraphQL literature insists that this new technology gives so much freedom to the client by allowing them to perform ad-hoc queries that you can safely have a single Backend without the drawbacks from REST-based approaches. You can take a look at this amazing article to get more insights of it.
Well, there are tons of articles which explain what GraphQL is and what are its advantages over REST ? but I would like to talk about the ones which I found really useful.
##Avoid under and over fetching
The most powerful feature of graphql is to avoid the problem of under and over-fetching. Basically using GraphQL, we are shifiting the autonomy to the client to request the data as much as it requires no more, no less.
So, in our case we were working on kind of social media application where we need to show the profile of other users including their images, and basic informations like (images, age, city etc). and we wanted it to be really blazing fast and with the traditional REST intuitive pattern, this would have required us at least two requests to two endpoints
GET /api/users
GET /api/users/1/profileBut, with GraphQL we can call this single API and prefetch all the data required.
query users {
id
name
city
age
avatars {
isProfile,
url
}
addresses {
type,
address
}
}So instead of multiple endpoints that return fixed data structures, a GraphQL server only exposes a single endpoint and responds with precisely the data a client requested.
##No API Versioning
While using REST, we version API's when we make changes to the resources or to the structure of the resources we currently have and calling the different versions of an API often times results in weird responses. for example
api.domain.com/v1/users
api.domain.com/v2/users
But, in GraphQL, it is possible to deprecate API's on a field level. When a particular field is to be deprecated, a client receives a deprecation warning when querying the field. After a while, the deprecated field may be removed from the schema when not many clients are using it anymore. Its too easy to deprecate a field if you are using apollo-server.
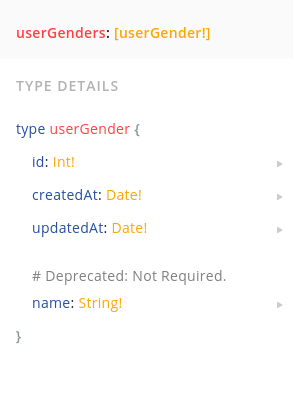
type userGender {
id: Int!
name: String! @deprecated(reason: "Not Required.")
createdAt: Date!
updatedAt: Date!
}And in GraphQL Playground, it will show the warning
 As a result, instead of completely versioning the API, it is possible to gradually evolve the API over time without having to restructure the entire API schema.
As a result, instead of completely versioning the API, it is possible to gradually evolve the API over time without having to restructure the entire API schema.
Also, adding new fields has no effect on any current clients because you only get the fields you request. ##Introspectable
For REST APIs, we need to use tools like Swagger to document the APIs but, GraphQL comes with its own inbuilt Playground, using which you can see your defined schema, It’s possible to query any GraphQL API to ask it about itself. Every compliant server has a __schema field which will allow you to retrieve information about the available fields and types. You can create your query, mutation, subscription etc all out there and see the results.
##Schema Stiching
So, this particular feature, I haven't got a chance to use it but this feature really embraces the Microservices Archietecture. Here, the backend would be broken down into multiple microservices with distinct functionalities. As a result, each microservice can define its own GraphQL schema.
Afterward, you could use schema stitching to weave all individual schemas into one general schema which can then be accessed by each of the client applications. In the end, each microservice can have its own GraphQL endpoint whereas one GraphQL API gateway consolidates all schemas into one global schema to make it available to the client applications.
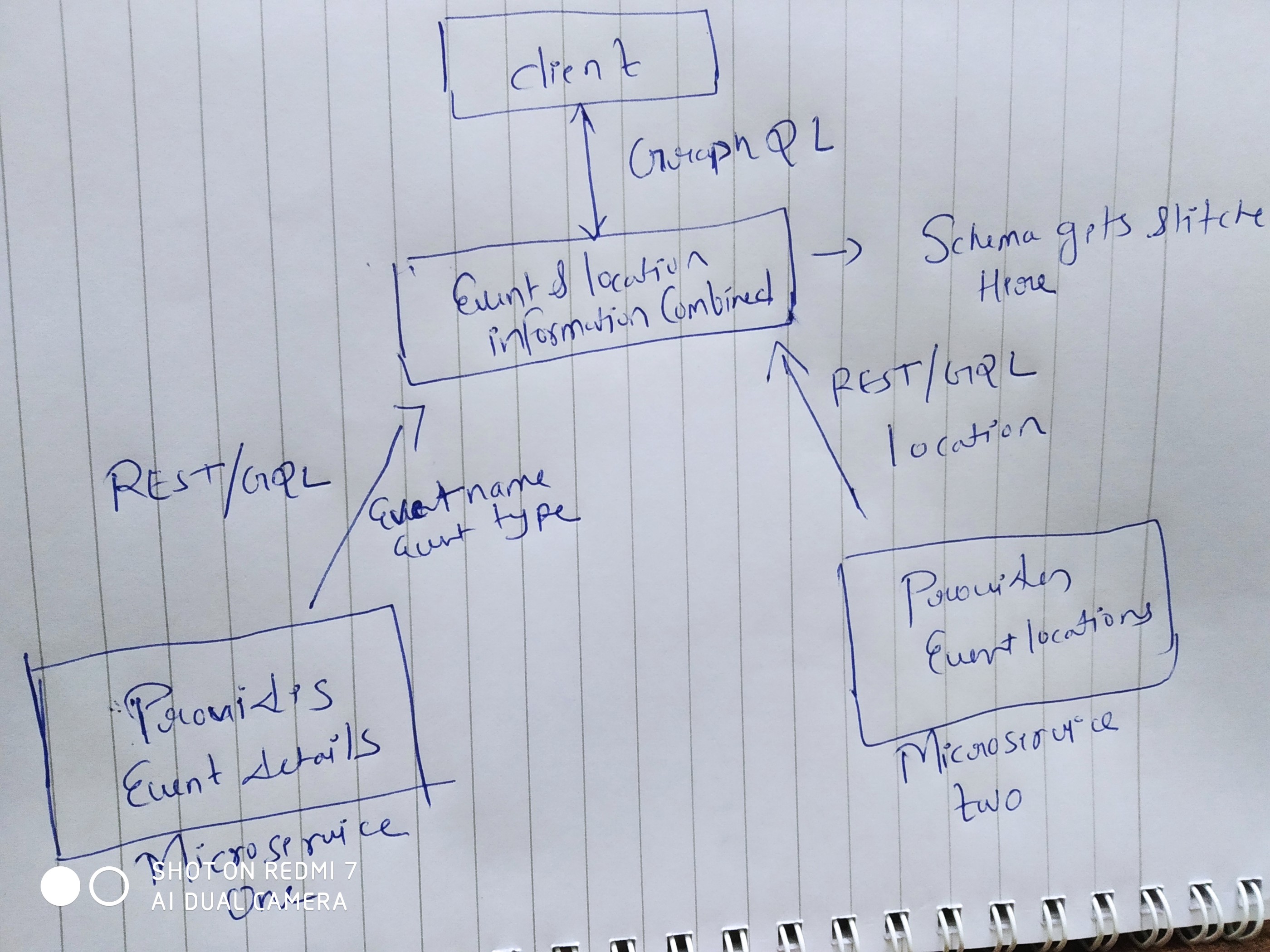
You can take an in-depth look at GraphQL Schema Stitching by Sashko Stubailo to get a deeper understanding of the concepts involved.
So, I have only mentioned the features which I have used and explored but there are lot more remaining and I would love to pen them down here as I use them.
##A Big "But"
So, the above features which I have mentioned don't come for free. Remember? what Uncle Ben said to Peter Parker With great power comes great responsibility. And here the onus is on the developers, to keep a keen eye on the problems mentioned below.
##(N+1) Problem
The one big gotcha with the GraphQL is (N+1) DB hits, So lets say we have schema like this
schema = `{
type Query {
users: [User]
}
type User {
id: Int
avatars: [Image]
}
type Image {
id: Int
isProfile: String
url: String
}
}`
resolvers = {
Query: {
users: async () => {
return await ORM.getAllUsers()
}
},
User: {
avatars: async (userObj, args) => {
return await ORM.getImagesFor(userObj.id)
}
},
}And the number of SQL queries would look like
SELECT *
FROM users;
SELECT *
FROM images
WHERE user_id in (1);
SELECT *
FROM images
WHERE user_id in (2);
SELECT *
FROM images
WHERE user_id in (3); This is where the name comes from, by the way. We will always make 1 initial query to the DB and return N results, which means we will have to make N additional DB queries. Now this is an intrinsic problem with the GraphQL and to solve this there’s a really handy tool that came out right alongside GraphQL called DataLoader.
Dataloader essentially wait for all your resolvers to load in their individual keys. Once it has them, it hits the DB once with the keys, and returns a promise that resolves an array of the values. It batches our queries instead of making one at a time. So, in above case it would just call the single IN query will all the userIds defined in it to fetch the images for them.
SELECT *
FROM images
WHERE user_id in (1,2,3); And I have used it extensively in my current project, will have a separate blog for the same.
##Freedoom to the Clients could be dangerous
GraphQL provides autonomy to the clients to execute queries to get exactly what they need. This is an amazing feature however, it could be a bit controversial as it could also mean that users can ask for as many fields in as many resources as they want. for example
query users {
id
name
posts {
id
description
comments {
user {
id
name
posts {
id
description
comments {
user {
id
name
}
}
}
}
}
}
}This query could potentially get tens of thousands of data in response and could even kill your server.
Therefore, as much as it is a good thing to allow users to request for whatever they need, at certain levels of complexity, requests like this can slow down performs and immensely affect the efficiency of GraphQL applications.
To avoid the mentioned problem, we can configue the Maximum Query Depth using which we could prevent the clients from abusing query depth like this. Do read the amazing article to get to know about the few strategies to mitigate these types of risks.
##Duplication of Schemas
When building with GraphQL on the backend, you would have some duplication and code repetition especially when it comes to schemas. First, you need a schema for your database(data models) and another for your GraphQL endpoint, this involves similar but, not quite identical code, especially when it comes to schemas.
It is really difficult that you have to write very similar code for your schemas and data models, but it's even more frustrating that you also have to continually keep them in sync.
Apparently, efforts have been made in the GraphQL community to fix it. PostGraphile, Prisma, Hasura etc. these tools generates a GraphQL schema from your database schema.
##My Take
The conclusion I arrived at when writing my GraphQL server was that GraphQL is not the elixir I thought it was. Though, all the features it advertised sounded incredible. Learning the schema language of GraphQL was not difficult. Once you learn about schemas, resolvers, object types, query and mutation you are ready to write your GraphQL server.
The only major problem I see with GraphQL is (N+1) DB hits, for which Dataloaders was introduced to resque but, coming from the REST background sometimes, I get confused while writing the GraphQL schemas say for example
type Query {
questions(id: ID!): [Question]!
}
type Question {
id: ID!
title: String!
type: String!
options: [Option!]
}So, here either I can define options as a field resolver and use Dataloader or get the entire data in a single query using joins which more sounds like a REST. So, In order to decide I think of the clients who are going to use these APIs. I would not use GraphQL in a simple application (for example, one that uses a few fields in the same way, every time) as it would add more complexity. but if I would have various clients, with different data requirements, I would use GraphQL without a doubt.